Pattern Recognition in Sectorial ETFs: (Highly) Automated Model
- H-Barrio

- Jan 12, 2021
- 4 min read
In our december publications we went over the development of an automated system that could determine which values (factors) had the highest historical predictive power from a pool of predetermined candidates. We are using sectorial ETF values as possible predictors of market behaviour in terms of directionality only. Our model did not perform very well and contained some embarrassing errors that caused the model not to behave as expected. The model is still under development and we are closer to the objective. As a reminder we are trying to:
Generate statistically appropriate factors. We are looking for stationary time series factors that provide good inference capabilities.
Automate the periodic selection of predictable variables and features (factors) inside the universe. This accounts for changing, evolving market conditions that our automated model has to react to.
Create a model that can properly account for the importance of a group of pre-selected factors. The pre-elected factors are evaluated independently from each other for predictive capacity and their combined effect in the model has to be modelled.
We are in a position in which points 1 and 2 are working although with certain limitations. Point 3 is not implemented as it will probably require moving from (relatively) simple sklearn classifiers to either more complex sklearn classifiers (using recursive feature selection, for example) or recursive neural networks.
In its current state the model implements a modified version of 8080Labs Predictive Power Score module that allows for data transformation and use of time series. This implementation of the module is still in development and can be found here. The objective of this module is to obtain the factor values that have shown the best historical predictive power in past.
The factors obtained by the prediction model are used to train automated classifiers that are assembled in a three-way voting array. The training of the models is not carried out in unison as sklearn 0.22 is still not available in Quantconnect. As soon as the version is updated a stacking classifier can be tested as a final classifier as an alternative to a recurrent neural network. Individual models are selected using a "pipe & grid" approach in which statistical transformations are fed (piped) into the model before performing a grid cross-validation selection. Currently both the piped statistical transformers and grid parameters are manually selected, these are assumed to have little impact on the predictive power of the model, an assumption that can always be verified after the rest of the model is working by "gridding" multiple such statistical transformers and letting the computer decide.
When the predictive models, using the factors and parameters selected by the machine, are trained it is ready to generate a consensus vote prediction that is limited to a binary "price up/down" signal with an automatically generated expiration date. Positions are entered accordingly and no further risk control or hedging is performed at his stage. We are trying to determine the performance of our prediction model only, its capability to generate above market and risk-adjusted returns can always be added on top of the predictive module. Basically we are assuming that overfitting risks are generated mainly in the predictive task and that historical correlation hedging can be added a posteriori considering it a minor backtest "sin" when compared to the major sin of overfitting a complex machine learned model.
The road we are following, consciously and aware of the risks, is that of sacrificing fully the explainability of the model to escape from overfitting to the past. Most risks and negativity associated to the "black box" nature of models like ours lies on societal impact (see, for example, this article on fairness) and possible discrimination of individuals which our model is not involved with directly. This road leads to a possible model that lacks (or minimizes) human inputted parameters and lets the machine decide, coldly, what are the best possible methods and data sets to be used for the task of predicting the markets. With enough memory space, processor speed and access to sufficient machine-readable data the whole process could be ultimately automated. In a simplified fashion: "Machine, here is the data and the market: obtain me profits".
An additional little technicality we have added into the model is a "moving threshold" calculation for the voting models. The targets, that is, market-up or market-down, can be very unbalanced in certain periods so that using a "0.5" selection threshold as the probability of a direction may not offer the best results. The implementation we have is similar to this external post.
So, finally, the most interesting question: is the model working?
Not yet.
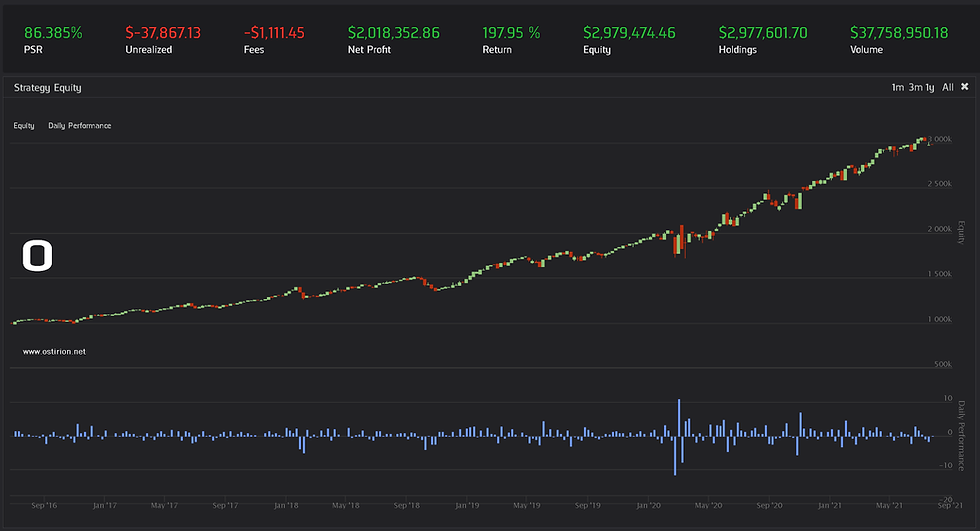
The model does take a good amount of time to run and gets confused very easily. We are letting the machine do the discoveries inside a limited pool of candidates, we are biasing the models a bit and the model generates a correct prediction 70% percent of the time. Still, when the market shifts, the model does not react well:

The model favours the 15 and 22 day look ahead predictions, is almost even in long-short positions (which is possibly good) and offers an overall compounding annual return of just 4% with an extremely long and deep drawdown. Something happens in May 2019 that sends the model off-track and is even incapable of detecting a strong bull market. The 2020 crisis goes through and the model keeps on confusing directions. The test is still useful as overall directionality of the generated signals is good:

The key now is to find a model, or set of models, than can better use the automatically found factors and target time frames. The first candidate will be a recurrent neural network that could improve the feature importance selection and even reduce the overfitting of each calculation iteration. Next steps can then add risk control and diversification of predicted assets in terms of their past correlation, as predicting a single instrument, unless perfectly predictable, will have a hard time providing good adjusted returns.
Information in ostirion.net does not constitute financial advice, we do not hold positions in any of the companies or assets that we mention in our posts at the time of posting. If you are in need of algorithmic model development, deployment, verification or validation do not hesitate and contact us. We will be also glad to help you with your predictive machine learning or artificial intelligence challenges.
Here is the code in its current state:

Comments