Pattern Recognition in Sectorial ETFs: Predictive Trading Model
- H-Barrio

- Dec 15, 2020
- 6 min read
Updated: Dec 16, 2020
The next-to-last step in verifying the capacity of sectorial ETFs to predict the price of the market in general or their own future behaviour is to develop a model that allows to backtest our previous research. Since the last publication we have made some changes to the Predictive Power Score calculator as developed by 8080Labs: we have implemented the time series split cross validation model and also added two fixed transformations into a pipeline: standard scaling and minimum-maximum scaling. This last change will transform the time series data into a more "statistically sound" set and enable our tree models to learn easier.
In this specific set of trials we are going to run through backtest combinations of factors and targets that are deemed interesting by our research engine. This will have an inherent limitation at this stage: the model will not be able to look for new and better factors for a predictor while the future happens. We will have to implement a function that prevents the predictive power from fading out, if we are to train a model based on the previous 5 years of data and expect it to run for another 5 validation years, the predictive power that was initially calculated may well be lost by the midpoint of the trial. We will cover this function early 2021 as the next publications will be the very special Ostirion Holiday Special and the review of the year just before 2020 ends.
For starters, let's try to run a backtest for the factors and target deemed more promising in our preliminary work. The symbols and factor identifiers are these:
factors = ['FSTA', 'KBWB', 'TDIV', 'KBWY']
factors_string = ['R_22_FSTA_PAST', 'R_66_KBWB_PAST', 'R_3_FSTA_PAST', 'R_66_TDIV_PAST', 'R_5_KBWY_PAST']
past = [3,5,22,66]
targets = ['IYM']
future = [22]
targets_string = ['D_22_IYM_FUT']We will run the decisions that the prediction model generates up to their end, indicated by a time limit "future" (22 in this case) days forward. We will just predict the direction of IYM (basic material ETF) 22 days into the future and buy or sell accordingly, no touching in between, no position closing, nothing strange yet as we want to see how the prediction itself, the naked prediction, behaves.
The available data will be run through the following "pipe and grid" model:
pipeline = Pipeline([
('scaler1', StandardScaler()),
('scaler2', MinMaxScaler()),
('rfc', RandomForestClassifier())
])
search_grid = {
'rfc__n_estimators': [50, 100, 200],
'rfc__max_features': ['auto'],
'rfc__max_depth': [5, 10, None],
'rfc__min_samples_split': [5, 10],
'rfc__min_samples_leaf': [1, 2, 4],
'rfc__bootstrap': [True],
'rfc__random_state': [random_state]
}
# Select a scoring function for the hyperparameter and feature selector.
# F1 is preferred for maximizing recall,
# relevance and weighting due to possibly highly imbalanced labels.
scoring = 'f1_weighted'
# Use the grid to search for best hyperparameters.
# First create the base model to tune.
# Search of parameters, using cross validation,
# search across different combinations, and use all available cores:
tscv = TimeSeriesSplit(n_splits=5)
self.model = GridSearchCV(estimator=pipeline,
param_grid=search_grid,
cv=tscv,
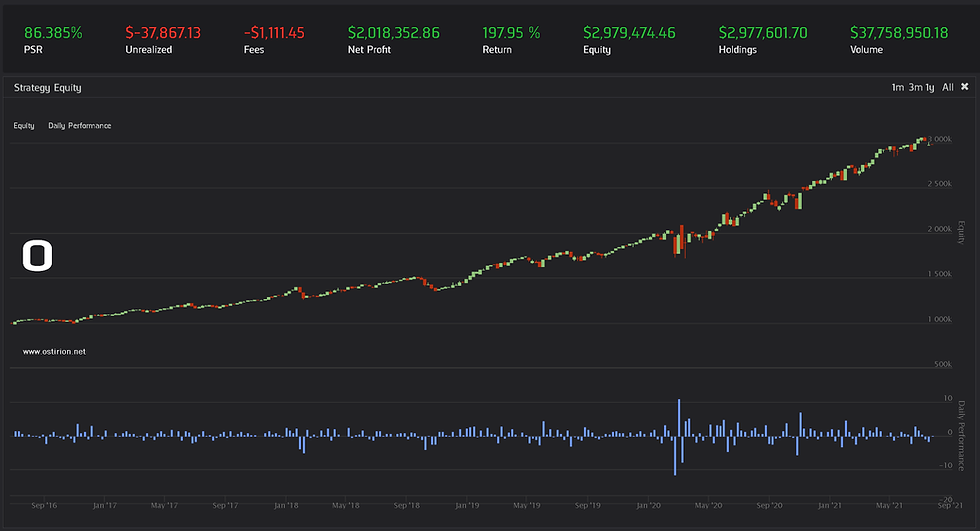
scoring=scoring)The backtest is then run for 5 years and the results are, not surprisingly, bad:

The model uses the 2011 to 2016 period to find the best possible predictors, the target instrument and future date that seem to offer the best predictability. Then the model will fit the random forest model every training period (60 days in simulation time, this can be adjusted) using approximately 5 years of data (requesting 1260 data points) and decide accordingly every trading period (set at 22 days in this case). The model should behave a bit better at the start of the test, it incurs in heavy losses with wrong shorting decisions, generated possibly from a negative trend in the target price that was prevalent in the training period, possibly reversed just as we commence trading at the start of 2016. This could be just (statistical) bad luck, and we are not letting our model correct itself as it is still trying to predict the same target, using the same factors, 5 years later after losing 30% of its portfolio value.
The first spot check has not been successful. Let's take a look at another approach for fixed target and predictors to gain more information on the basic capabilities of the model. We return to our research model and instead of letting the process find both target and factors, we will fix the target to a simple instrument, SPY or QQQ, "the market", whose behaviour should be anticipated by the sectorial ETFs when aggregated, and find a set of factors for shorter-term trading windows, in principle, easier to predict:
self = QuantBook()
targets = ['QQQ', 'SPY']
#TPYP dropped, as the inception date is in 2015 and leads to erros.
#factors = ['IYM', 'XHB', 'FSTA', 'KBWB', 'IXJ', 'XLI', 'KBWY', 'TDIV', 'IXP', 'RYU', 'IGE']
# Traditional Sector ETFs for alternate analysis:
factors = ['XLK', 'XLY', 'XLC', 'XLB', 'XLV', 'XLP', 'XLI', 'XLU', 'XLF', 'XLE', 'IGE']
start = datetime(2010, 1, 1)
end = datetime(2015, 1, 1)
factor_symbols = {factor: str(self.AddEquity(factor).Symbol.ID) for factor in factors}
target_symbols = {target: str(self.AddEquity(target).Symbol.ID) for target in targets}
all_symbols ={**factor_symbols, **target_symbols}We are also using the X-series sectorial ETFs (the more 'classic' State Street GA funds), in this case, looking for consistent tracking across sectors. We do not eliminate the lack of data, the youngest of these ETFs was created in 2018. The research notebook from our previous publication can be executed much faster using this approach, we do not have 320 targets to be evaluated, we have 2 targets times the number of time-frames we want to analyze. The results for the "best possible" predictions using this method are:

Well, we will rig our model then to predict the direction of QQQ 22 days into the future using the 15 day price of XLF and the 10 day returns of XLU as factors. Running the same simple backtest yields again very bad results, a 40% loss in 5 years, the capacity of the model to predict the direction is of interest:

Is good at the start of the test, generates 3 months of good directional predictions, and after that... after that it inexorably falls to a 35% mean directional accuracy. We note that the preference of the model is to short QQQ 75% of the time, the AI missed the news on the the longest bull run ever. The model apparently learns some bad habits from the past and cannot adjust to the present very well. If we let the model predict always the same combination of instrument, time frame and factors it quickly loses money to the ebb and flow of the market.
In its present state the model is of no great use, it is fitting to a very static past while the future comes fast at it. There is a secondary effect in play regarding the construction of the factors: we are using a single variable predictive power analysis and mixing them later into a multivariate prediction without paying any attention to their interactions. Our random forest classifier model may not be the best fit for a group of factors individually selected, then mixed, the interactions can result in very negative conclusions when taken collectively. Another model could help us here in factor weighting and possibly we will need to use a heavier neural network to get value out of feature importances (collectively) for the factors we have previously selected by their high individual predictive power.
The model apparently needs the following modular functions to work properly:
Optional and very nice to have: fractional differentiation of the pricing values used as factors. Stationary factor series could improve the inference capabilities.
Automatic and periodic re-selection of predictable variable and features (factors) inside the universe. This would account for changing, evolving market conditions.
A machine learning model that can properly account for the importances of a group of pre-selected factors.
We will implement these improvements incrementally and comment the results starting 2021. The following weeks we will post our Holiday Special and End of the Year analysis of the market that was 2020 COVID19, with the intention of predicting 2021, hoping for it to be, if not good, at least normal.
Our usual disclaimer: Information in ostirion.net does not constitute financial advice, we do not hold positions in any of the companies or assets that we mention in our posts at the time of posting. If you are in need of algorithmic model development, deployment, verification or validation do not hesitate and contact us. We will be also glad to help you with your predictive machine learning or artificial intelligence challenges.

Comments