Primary Data Sources: Geographical Data from WFS
- H-Barrio

- Jun 1, 2021
- 6 min read
Updated: Jun 7, 2021
Data is the new oil. Data is the new gold. The mithril of Moria. These phrases are used to emphasize the value of data in the current economy and the predicted increase of its value in the future. We will not discuss it, we will assume that data has value, and like gold and oil, it requires extraction and refinement to be of use to the economy.
Today we will present an example of primary data extraction and refinement. This primary data is not financial in nature. Recently we needed to check some rail transportation network data in Spain, and we will show this specific data group as an example. The objective of the task is to obtain the geographical positions and metadata of the rail network infrastructure for further analysis. Machine learning and artificial intelligence models work in mysterious ways; you never know what type of data you will need or how deep it is buried in the mine.
The notebook for this post is shared below, at the end of the post.

The dataset in question is published by the Spanish national rail network authority, ADIF, through their "Web Feature Service". Data for geographical information is generally Geographic Markup Language (GML) encoded. This is a venerable dataset and uses this XML dialect instead of the more "modern" JSON format. This data is thus not on the planet's surface (Google queries); it is buried behind several layers of formalities that we need to dig through before reaching the raw data.
Python may be slow to process computations; it is also fast to develop in and so contains simple libraries for almost everything. The library we need to access these Web Feature Services is OWSlib, a part of the GEOPython organization for geographical information tools.
If OWSlib is not installed in your system (it is not, by default, in Google Colab), you can install OWSlib using:
!pip install owslibWe have to create the WFS connection object. For this, we need the service URL and the version of the communication protocol:
wfs_url = 'http://ideadif.adif.es/gservices/Tramificacion/wfs?request=GetCapabilities'
wfs = WebFeatureService(url=wfs_url, version='1.1.0')The URL is the one specified by the service provider on their webpage. You can always access it via browser to check a difficult to read GML file here:
We are using version WFS 1.1.0 for stability and documentation. WFS 1.1.0 XML dialect structure appears to easier to parse than 2.0.0, although the process we present here may be ugly.
We can check that the service we are accessing is indeed what we need:
wfs.identification.title
#IDEADIF - GeoServer WFSWe can check the operations available to us and the information content:
[operation.name for operation in wfs.operations]
#['GetCapabilities', 'DescribeFeatureType', 'GetFeature', 'GetGmlObject']
list(wfs.contents)
#['Tramificacion:Dependencias',
'Tramificacion:PKTeoricos',
'Tramificacion:TramosServicio',
'Tramificacion:TramosFueraServicio']The data scheme for each of the contents can be checked using:
print("Dependencias: " + str(list(wfs.get_schema('Tramificacion:Dependencias'))))
print("PKTeoricos: " + str(list(wfs.get_schema('Tramificacion:PKTeoricos'))))
print("TramosServicio: " + str(list(wfs.get_schema('Tramificacion:TramosServicio'))))
print("TramosFueraServicio: " + str(list(wfs.get_schema('Tramificacion:TramosFueraServicio'))))
'''
Dependencias: ['properties', 'required', 'geometry', 'geometry_column'] PKTeoricos: ['properties', 'required', 'geometry', 'geometry_column'] TramosServicio: ['properties', 'required', 'geometry', 'geometry_column'] TramosFueraServicio: ['properties', 'required', 'geometry', 'geometry_column']
'''The schema for each of the data contents is similar, so to get the feature we require, we use:
theo_kmpoints = wfs.getfeature(typename='Tramificacion:PKTeoricos')We assign the results of a feature request for the theoretical kilometer points representation of the rail network. This is an _io.BytesIO object that we can read and decode into UTF-8. The Unicode Standard is here if you wish to check the contents of the standard.
byte_str = theo_kmpoints.read()
# Convert to a "unicode" object
kmpoints_text = byte_str.decode('UTF-8') The result is now an extensive text showing an XML-like structure. We can partially check the contents for a general shape check with:
kmpoints_text[0:2000] # First 2000 charactersThe contents of the text can be saved to a GML file for later use if needed:
out = open('theo_kmpoints.gml', 'wb')
out.write(bytes(kmpoints_text, 'UTF-8'))
out.close()This text format file has to be parsed so that we can read it like a Python dictionary. We need a couple of additional tools to simplify the parsing process: the Python XML parser and two classes to hold the data into dictionaries and lists, based on this recipe:
from xml.etree import cElementTree as ElementTree
class XmlDictConfig(dict):
def __init__(self, parent_element):
if parent_element.items():
self.update(dict(parent_element.items()))
for element in parent_element:
if element:
if len(element) == 1 or element[0].tag != element[1].tag:
aDict = XmlDictConfig(element)
else:
aDict = {element[0].tag: XmlListConfig(element)}
if element.items():
aDict.update(dict(element.items()))
self.update({element.tag: aDict})
elif element.items():
self.update({element.tag: dict(element.items())})
else:
self.update({element.tag: element.text})
class XmlListConfig(list):
def __init__(self, aList):
for element in aList:
if element:
if len(element) == 1 or element[0].tag != element[1].tag:
self.append(XmlDictConfig(element))
elif element[0].tag == element[1].tag:
self.append(XmlListConfig(element))
elif element.text:
text = element.text.strip()
if text:
self.append(text)The XML dictionary (GML in reality) is thus:
root = ElementTree.XML(kmpoints_text)
xmldict = XmlDictConfig(root)What is in this dictionary? The GML structure can be complex as it is a multi-layer standard that may repeat empty entry keys or nest data "too deep into the earth" depending on the content we want to access. This is where the digging starts. First of all, the first level of dictionary entries are:
dict_keys = list(xmldict.keys())
dict_keys
'''
['numberOfFeatures',
'timeStamp',
'{http://www.w3.org/2001/XMLSchema-instance}schemaLocation', '{http://www.opengis.net/gml}featureMembers']
'''The number of features, the timestamp, the location, and finally, the members of the data package. We have generated a list with the first level keys as now we can access this first level by calling the numeric position of the key for our "prospection" needs:
print('Number: ' + xmldict[dict_keys[0]])
print('Time: ' + xmldict[dict_keys[1]])
print('Location: ' + xmldict[dict_keys[2]])
print('Members: ' + str(type(xmldict[dict_keys[3]])))
We can print almost everything, but not the "members" entry, as this is where the data dictionary is located; we print a string representation of the class to prevent an error.
Number: 16824
Time: 2021-05-28T07:54:28.134Z
Location: http://ideadif.adif.es/tramificacion http://ideadif.adif.es:80/gservices/Tramificacion/wfs?service=WFS&version=1.1.0&request=DescribeFeatureType&typeName=Tramificacion%3APKTeoricos http://www.opengis.net/wfs http://ideadif.adif.es:80/gservices/schemas/wfs/1.1.0/wfs.xsd
Members: <class 'dict'>The data we are looking for is behind this "vein", in the index entry 3 of the package dictionary and still inside a singleton entry inside a list:
km_points_data = list(xmldict[dict_keys[3]])
km_points_data
# ['{http://ideadif.adif.es/tramificacion}PKTeoricos']Raw data is thus inside the first list entry inside the index 3 dictionary key:
raw_data = xmldict[dict_keys[3]][km_points_data[0]]To make sure we struck the gold or the oil, we can inspect a random data entry, as we are supposed to have 16824 of those:
raw_data[80]
'''
{'{http://ideadif.adif.es/tramificacion}codtramo': '022000050', '{http://ideadif.adif.es/tramificacion}geom': {'{http://www.opengis.net/gml}MultiPoint': {'srsDimension': '2', 'srsName': 'urn:ogc:def:crs:EPSG::25830', '{http://www.opengis.net/gml}pointMember': {'{http://www.opengis.net/gml}Point': {'srsDimension': '2', '{http://www.opengis.net/gml}pos': '454114.02219999954 4476900.4242'}}}}, '{http://ideadif.adif.es/tramificacion}id_provinc': '28', '{http://ideadif.adif.es/tramificacion}pk': '15.3', '{http://www.opengis.net/gml}id': 'PKTeoricos.81'}
'''This is the "ore", we have a code for a section of the railway network, the description of the geographical metadata of the point in question, the coordinates of the point in question (in EPSG25830 standard), an identifier code for the province of Spain in which the point is located, the kilometer point number for the section and the identifier, 81, as this is the entry at index 80. Premium "data ore", 16824 entries of data that we need to refine for simplified use.
Refining this data for consumption by the data industry while using Python involves turning this set of entries into a pandas data frame. We will have to rid ourselves of the repeat data in each entry: the geometrical metadata is always EPSG25830, as it is redundant in this particular case. As data is already in dictionary form, a simple, ugly, and unpythonic approach is to split every data element into individual dictionaries to construct a data frame with them. We can enter the data elements for each entry into a list for easy accessing:
data_elements = list(raw_data[0].keys())
data_elements
'''
['{http://www.opengis.net/gml}id', '{http://ideadif.adif.es/tramificacion}geom', '{http://ideadif.adif.es/tramificacion}pk', '{http://ideadif.adif.es/tramificacion}codtramo', '{http://ideadif.adif.es/tramificacion}id_provinc']
'''Of these data elements, all but the geometry information are readily available. Geometry coordinates are buried deep into the data schema. As an example, for entry index 0, the coordinates we are looking for are here:
MultiPoint->pointMember->Point->pos
raw_data[0][data_elements[1]]['{http://www.opengis.net/gml}MultiPoint']['{http://www.opengis.net/gml}pointMember']['{http://www.opengis.net/gml}Point']['{http://www.opengis.net/gml}pos'] For a position string of 373512.03729999997 4495357.6887.
Our extraction loop looks like this then, with the ugly extraction of coordinates for data elements at index 1:
total_points = len(raw_data)
total_points
coords = {}
km_points = {}
section = {}
province = {}
for elem in range(total_points):
index = raw_data[elem][data_elements[0]]
coords[index] = raw_data[elem][data_elements[1]]['{http://www.opengis.net/gml}MultiPoint']['{http://www.opengis.net/gml}pointMember']['{http://www.opengis.net/gml}Point']['{http://www.opengis.net/gml}pos']
km_points[index] = raw_data[elem][data_elements[2]]
section[index] = raw_data[elem][data_elements[3]]
province[index] = raw_data[elem][data_elements[4]]Every point is now indexed by the corresponding "id" value of the entry, with coordinates, point, section, and the province as separate dictionaries using this same index. It is simple now to create a data frame from consistently indexed dictionaries:
import pandas as pd
pk_dataframe = pd.DataFrame([coords, km_points, section, province]).transpose()
pk_dataframe.columns = ['coords', 'km_point', 'section', 'province']
pk_dataframe.head()For a final form of refined data, premium state pandas data frame, a nugget:
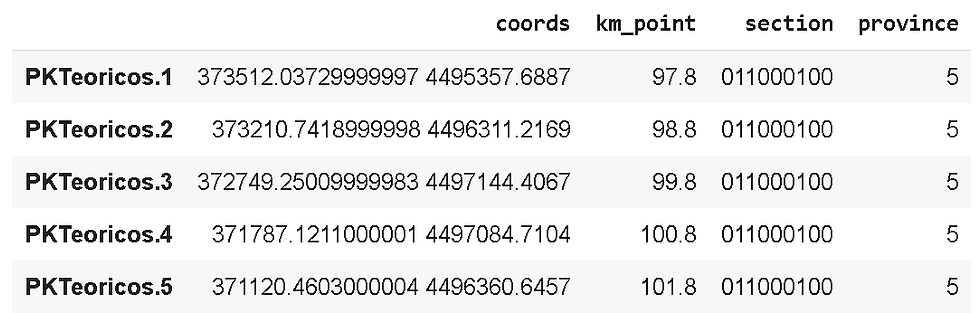
Finally, we send it into a CSV file for portability:
pk_dataframe.to_csv('PKTeoricos_ADIF.csv')In our next post, we will exploit this data a little bit and simply represent and locate these points of the railway network on a map using Folium.
If you require quantitative model development, deployment, verification, or validation, do not hesitate and contact us. We will also be glad to help you with your machine learning or artificial intelligence challenges when applied to asset management, automation, or risk evaluations.
Link to the Google Colab notebook: Notebook.

Comments