All Tomorrow's Parties - Identifying Largest Market Moves Using Deep Learning (Part IV)
- H-Barrio

- Oct 28, 2020
- 4 min read
In this post, the last part of the All Tomorrow's Parties model series, we are going to backtest our deep network while it attempts to predict the top and the flop (the best and worst performing stocks) of tomorrow.
Deep neural networks behave, by their nature, stochastically, and it is good practice to test the same predictive model over multiple backtests (experiments) to check its dependence on luck. In general, the worse the adaptation of our neural network is to the phenomenon we want to predict, the higher its dependence on luck and the more variance there will be in experimental results. If our model can adapt very well to the variables that predict our phenomenon, on the other hand, dependence on luck will be very low and experimental results (the backtests) will generate very similar results.
We can illustrate this effect by running two backtests of the same model. In this case, and to make the test relatively quick, this simple model:
n_out = len(targets.columns)
n_layers = 5
width = 10
self.model = keras.Sequential([])
self.model.add(layers.Dense(width, activation="tanh", name="layer1"))
self.model.add(layers.Dropout(0.6))
for i in range(n_layers):
self.model.add(layers.Dense(width, activation="tanh", name="Denselayer"))
self.model.add(layers.Dropout(0.2))
self.model.add(layers.Dense(n_out,activation='tanh'))After adapting the code from our previous installments to handle all possible prediction cases (short days, missing stock prices for certain periods...) we obtain the following results, let' s call them run 1 and run 2:


The universe is limited to the top 10 highest capitalization and traded volume stocks. The directional prediction accuracies for both runs are:


And the symbols each of the runs preferred to predict as top or flop are:


The differences are apparent in the returns charts, predictive capacity and traded stocks indicators. To prevent this effect from clouding model comparisons we can set the random seeds of our models to gain a certain level of reproducibility, the following lines of code should be at the very beginning of our models to ensure that all randomly initialized variables from import statements make use of the same seed:
from numpy.random import seed
r_seed = 2127
seed(r_seed)
from tensorflow import set_random_seed
set_random_seed(r_seed)It is interesting to note that the simple model, the test model, may have a little bit of directional stock predictive power (51% directional score), not enough to generate sufficient positive returns as seen in the mean insight value and alpha indicators.
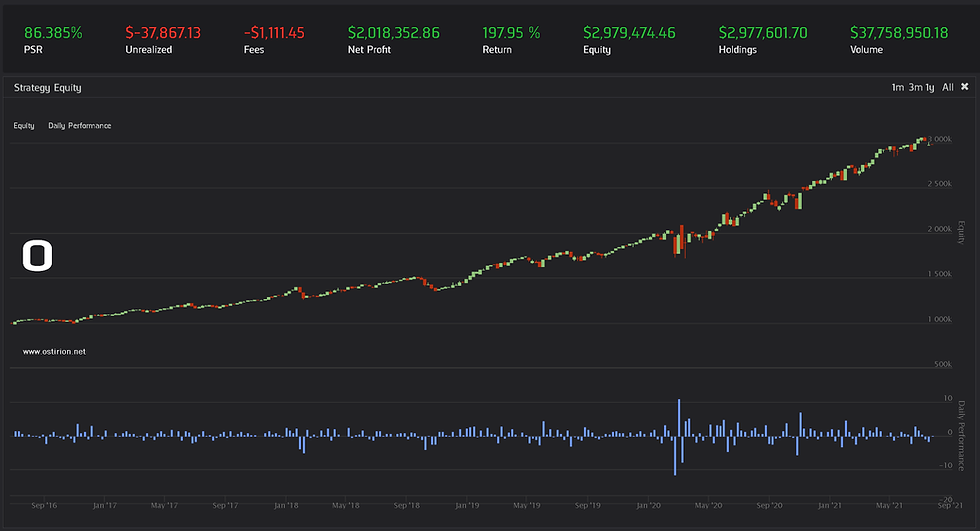
Now, the moment of truth; running a backtest for our best model, as defined by our research efforts, we obtain the following results:

Quite anticlimactic after 3 hours of backest computation. The model does not manage to provide positive returns in 5 years while training monthly with the past 5 year´s data. The effective annual return of the model is -8.5%, with two or three periods in which the training and prediction models are invalid due to missing data. This last problem is easily solved, if a machine learning model fails to provide a prediction you can always fall back into uncorrelated safe assets and at least deploy the cash effectively. The returns problem is more difficult to tackle, this model is for the highest 50 traded capital stocks and the top/flops pattern seems partially hidden, is difficult to predict. The key performance of our predictions offers more interesting information:

There is a small advantage in our favor in direction score, may be normal as we are looking for the largest moves in both directions, even if the model does not hit the top or the flop, at least the directionality should show positive lift. There is a little bit of value to the predictions but the errors are critical, when the top or the flop we are seeking lets us down we incur in large losses for the day. Even fees are not significant at a maximum of two round-trip operations per day. The model seems to be bad, the problem seems too hard to predict with hourly resolution data for price and volume. This neural network cannot find a pattern in it.
At this stage it is possibly better to go back to the drawing board and reset the complete problem definition and approach, lest we fall into the trap of extreme backtesting and the accompanying sin of overfitting. If a model shows little promise in backtest after acceptable performance during research it is sensible to stop back-testing. Let me quote here the abstract from Marcos Lopez de Prado´s presentation notes on backtesting:
"Empirical Finance is in crisis: Our most important "discovery" tool is historical simulation, and yet, most backtests published in leading Financial journals are flawed.
The problem is well-known to professional organizations of Statisticians and Mathematicians, who have publicly criticized the misuse of mathematical tools among Finance researchers. In particular, reported results are not corrected for multiple testing. To this day, standard Econometrics textbooks seem oblivious to the issue of multiple testing. This may invalidate a large portion of the work done over the past 70 years."
If enough backtesting is carried out we will eventually fine tune the model until we make it profitable in the past, doubtedly so in the future. Before we shelve the model for later reinterpretation, and just out of curiosity: how would the model behave with just 2 stocks? It has to identify the one that moves the most up and the most down, so it will always keep us into both of them:

Less noise and less loss, no positive returns. It becomes a GOOG, AMZN, AAPL and MSFT long-short weaving that leaves us a little bit worse than we started. The model requires more profound changes for sure. Back to the research board.
Remember that information in ostirion.net does not constitute financial advice, we do not hold positions in any of the companies or assets that we mention in our posts at the time of posting. If you are in need of algorithmic model development, deployment, verification or validation do not hesitate and contact us. We will be also glad to help you with your predictive machine learning or artificial intelligence challenges.

Comments