Predicting Volatility: Final Random Forest Model & All the Shots you Don't Take
- H-Barrio

- Aug 25, 2020
- 3 min read
In this post we present the final form of our volatility prediction machine learning model. In our last installment we raised the following possible actions for improving the predictive capacity of the model:
Meta-labelling the predictions to discriminate good from bad.
Setting up prediction accuracy thresholds.
Add more relevant prediction factors.
We have not been able to follow through with this list. Meta labelling the trades has been the most effective technique, prediction accuracy has been substituted by prediction discrimination and finding more relevant factor is going to take, optimistically, weeks of research. For determining the feasibility of this prediction it proved better to just take the low hanging fruit; generate a stable working model and find additional factors taking more time and with the security that the model is not fundamentally flawed.
Using the "spirit" of meta-labelling, discriminating trades that we do not need to make, we found that the prediction capacity of the model, as time goes by, varies greatly with the market regime. Looking at the confusion matrix for a period between 2004 and 2015 we obtained these results:

And whatever the period that is taken, the imbalanced confusion matrix is there. In this period the labels are balanced 1068 to 952. This image is taken from wikipedia article for confusion matrix, showing all the possible factors that can be evaluated in a binary classifier:

We have Positive Predictive Value and Negative Predictive Value imbalances in the trained model. It can predict very well a single direction most of the time, but is no better than 50% in the other. This evolves with time, every time we update the training of our model with a new batch of data, 22 new trading days for instance, the balance slowly changes. During 2011 - to 2015 the Negative Predictive Value, predict VIX goes down, is higher than the Positive Predictive Value, even if the set of data is almost perfectly balanced between VIX up and VIX down. In this period, with monthly training, PPV and NPV preference ratio is 0.25 - 0.75.
The literature on confusion matrix is concentrated in the medical field, where correct diagnosis is critical and there is no "no-trade" option, there is no "no-answer" option. Thankfully algorithmic trading is not as safety-critical as the medical field and we can select not to trade from time to time. We recently attended a seminar by The Thalesians in which Ernest P. Chan explained how their machine learning trading model makes a lot of no-trade decisions, in agreement with Marcos Lopez de Prado´s metalabelling views (around minute 24). Now it becomes a problem of managing our customers to convince them that cash is the best holding during these "no decision" periods and take only those trades that our machine model says are accurate. We may hit with some shots we won't take, sorry Gretzky.
We took our inspiration from the multiple images of doctors as they "false-positive" a pregnant man. The point here is, we can decide not to diagnose. With this in mind, discriminating each training period for the highest Predictive Value we end up with this:

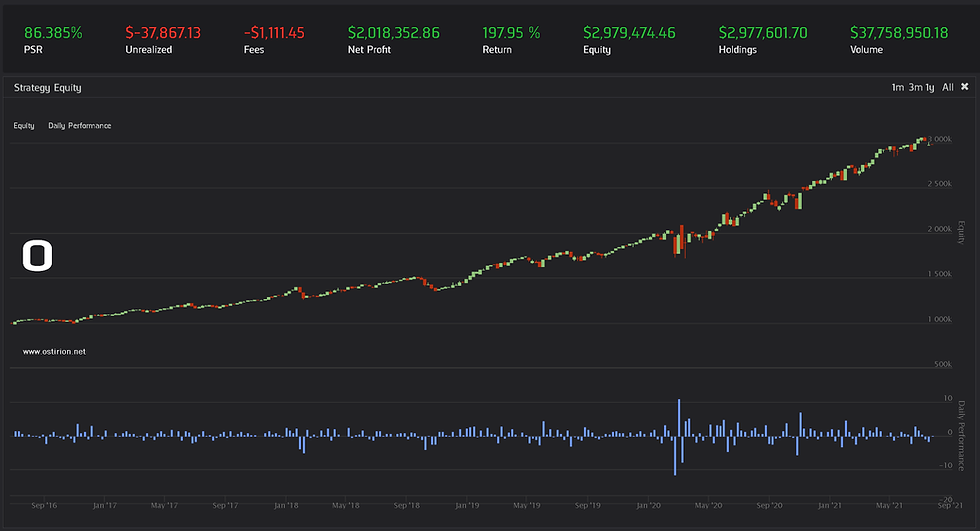
The model will trade VIXY as it is the closest possible instrument to VIX available to us. If the prediction does not match the highest value prediction (PPV or NPV) it abstains from predicting anything and generates those small training gaps in 2016, 2017 and 2018 and decides that 2019 did not exist, only the random forest knows why as we have not been able to find a sensible explanation. The accuracy of the taken shots is as follows:

66% of the directional predictions were correct. The model generates a daily prediction at market close valid for the 5th day in the future, no intermediate corrections are implemented. The model prefers predicting a decreasing VIX, with a long-short ratio for VIXY of 0.26.
The model is difficult to use "as is" due to the impossibility to predict how many trading signals we will have in a given year, or the expected return of the trades (without heavy overfitting). It could be very useful as a back-up plan or supported by a back-up plan that provides non-interfering signals. We will continue developing this model, with better decision factors, with the aim at removing the bias and be able to obtain high accuracy in all market conditions. It is also a possibility that instead of using VIX related ETFs or ETNs there is a better method to capitalize from a volatility prediction with options over SP500 members, using options greatly increases the complexity of trading algorithms and will require careful planning not to end up with unacceptably high risks.
Remember that publications from Ostirion.net are not financial advice. Ostirion.net does not hold any positions on any of the mentioned instruments at the time of publication. If you need further information, asset management support, automated trading strategy development or tactical strategy deployment you can contact us here.

Comments